
Welche Individualisierungen sind möglich?
Es gibt drei Möglichkeiten zur Individualisierung neuer KI-Szenen:
1) TEXT2FILTER - Einzelszene -> Interpretiert Menschen in neuen Posen und Szenen
2) TEXT2FILTER - Gruppenszene -> Bewahrt die ursprüngliche Pose. Kleidung, Szene und Hintergrund werden generiert (für 1-5 Personen gut nutzbar)
3) IMAGE2FILTER - Einzelperson -> Es besteht eine feste Bildvorlage, bsp. nur der Kopf wird durch Maskierung ausgetauscht.
Die drei Möglichkeiten sehen Sie nachfolgend grafisch aufbereitet als Übersicht. Anschließend wird die Funktionsweise der einzelnen Möglichkeiten detailliert dargestellt.
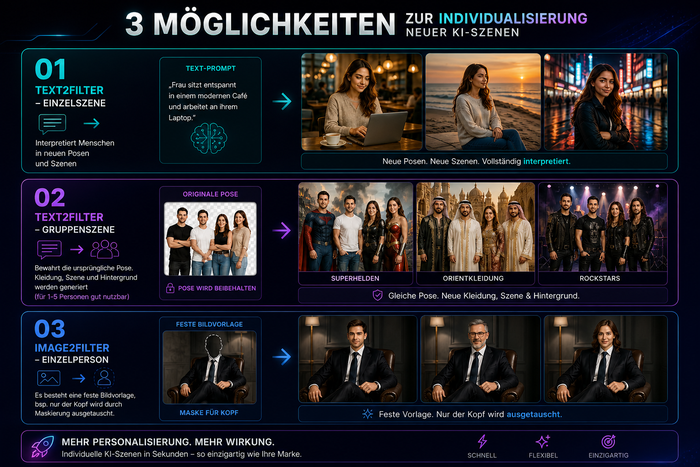
1) TEXT2FILTER - Einzelszene
Mit Faceswap Text2Filter werden Filter direkt per Texteingabe.
Beschrieben wird der Look oder Stil, und die KI passt das Gesicht des Nutzers automatisch an die Vorgaben an.
Mit Text2Filter können personalisierte Filter mithilfe von Texteingaben erstellt werden. Durch einfaches Beschreiben des gewünschten Stils oder Aussehens verwandelt Text2Filter sie automatisch in die vorgegebene Szenerie, wobei Ihr Aussehen grds. erhalten bleibt, es sei den Promt beschreibt bsp., dass Männer immer lange Haare haben.
Wie sollte die KI-Szene am besten beschrieben werden?
V6 (aktuelle Version 04/2026) funktioniert am besten mit einer klaren, strukturierten visuellen Beschreibung. Lange Anweisungen sind nicht nötig – folgen Sie einfach der Grundformel und halten Sie es visuell.
V6-Formel
[PERSON] [OUTFIT] [AKTION/POSE] [SCREENING] [STYLE/DETAILS]

Für alle zu erstellenden kundenindividuellen KI-Filter erfolgt Test- Qualitätssicherung, damit die Filter bestmöglich funktionieren.

Damit der Promt gut funktioniert …
- Formulierung PERSON (immer).
- Anweisungen visuell und direkt.
- klare Szene
- aussagekräftige Schlüsselwörter.
- Ganzkörperanalysen sind am besten geeignet
Was man vermeiden sollte
- Mann/Frau statt PERSON schreiben
- Zu viele Ideen in einer einzigen Aufgabenstellung
- Abstrakte Konzepte, die schwer zu visualisieren sind
- Masken oder bedeckte Gesichter
- Extreme Kameraveränderungen gegenüber dem Eingangsfoto
Letzter Tipp:
Sollten die Ergebnisse nicht funktionieren, vereinfachen Sie die Eingabeaufforderung und bauen Sie sie Schritt für Schritt neu auf oder aktivieren Sie unsere Eingabeaufforderungsvorschläge, um
die perfekten Eingabeaufforderungen zu erhalten.
2) TEXT2FILTER - Gruppenszene (auch Einzelpersonen)
Mit MultiSwap Text2Filter erstellen wir eigene Filter für bis zu fünf Personen – per Texteingabe.
Beschreiben Sie einfach den gewünschten Stil, die Szene oder das Outfit, und die KI verwandelt Ihre Gruppe in visuell beeindruckende
Ergebnisse – ganz ohne die Identität, Pose und Emotionen der einzelnen Personen zu beeinträchtigen.
MultiSwap ist in zwei Modellversionen erhältlich:
- Realistischer Modus – legt Wert auf lebensechte Genauigkeit und bewahrt natürliche Gesichtszüge und Mimik beim Wechsel von Kleidung oder Szenen.
- Stilisierter Modus – verwandelt Ihre Gruppe in künstlerische, kreative Interpretationen wie Gemälde, 3D-Renderings oder animierte Stile.

Nachfolgend sehen Sie ein Beispiel eines Kunden, der individuelle Szenen für den Messestand eines Landwirtschaftbauunternehmens wünscht zum Schutz von Pflanzen bzw. globaler gedacht der Erde.
Nachfolgend haben wir eine apokalyptische Szene erstellt, in der die Welt im Hintergrund brennt, im Vordergrund steht die fotografierte Person. Zusätzlich haben wir im Promt eine Interkation genannt, hier, dass in den Händen die Erde gehalten werden soll.
Bei Auswahl dieser KI-Szene hatte mein Kunde den Messegästen die Szene erklärt und animiert, dass man ein Foto macht als wenn man die Erde halten würde. Insbesondere bei mehreren Personen ist das interessant, wenn die Personen einen unsichtbaren Gegenstand halten und dann die Erde erst im Endergebnis digital hinzugefügt. Überwiegend funktioniert das sehr gut, aber bei KI können einzelne Fehler noch auftreten, dann macht man einfach ein zweites Bild und der Gast freut sich trotzdem.

3) IMAGE2FILTER - Einzelperson V6
Anhand einer Bildvorlage wird der Promt auf einen zu maskierenden (ersetzenden) Bereich angewendet.
Man teilt dem Model mit , wer ersetzt wird und optional, was es tragen soll .
Das Ausgangsbild definiert bereits Szene, Pose, Beleuchtung und Komposition , daher sollte die Aufgabenstellung nur beschreiben, was ersetzt wird .
- Das Bild/die Szene ist der Hauptfaktor für den Filter.
- Das Ändern des Bildes hat eine größere Auswirkung als der Versuch, den Filter über die Eingabeaufforderung zu ändern.
- Outfitbeschreibungen sind möglich. Sie sollten kurz und prägnant sein .
Was man hier beim Prompten vermeiden sollte
- Pose nicht beschreiben.
- Umgebung nicht beschreiben.
- Nicht die Gesamtszene umschreiben.
- Keine langen filmischen Anweisungen.
- Weder Kamerawinkel noch die Perspektive ändern.
Folgende Maskierungen sind im Basisbild möglich:
- nur der Kopf -> dabei wird nur der Kopf im Basisbild maskiert und ausgetauscht
- Kopf und Haut -> neben dem Kopf wird auch die Haut getauscht bsp. bei kurzer Kleidung mit sichtbaren Armen
- Ganzkörpermaske -> der komplette Körperbau wird ausgetauscht
Welche Art von Ausgabebildern kann erstellt werden?
Neben einer klaren Aufgabenstellung und dem Eingabefoto hat insbesondere die Ausgabeszene einen großen Einfluss auf die Ausgabequalität.
Der wichtigste Faktor für qualitativ hochwertige Ergebnisse ist, wie viele Pixel das Gesicht im Bild einnimmt .
- Größere Gesichtsfläche → Mehr Gesichtsdetails werden erfasst
- Mehr Details → Bessere Identitätsrekonstruktion
- Bessere Rekonstruktion → Höherer Realismus
Nahaufnahmen von Porträts liefern i. d. R. die besten Ergebnisse, da sich das Modell auf die Gesichtszüge konzentrieren kann, anstatt seine Ressourcen über eine große, komplexe Szene zu verteilen.
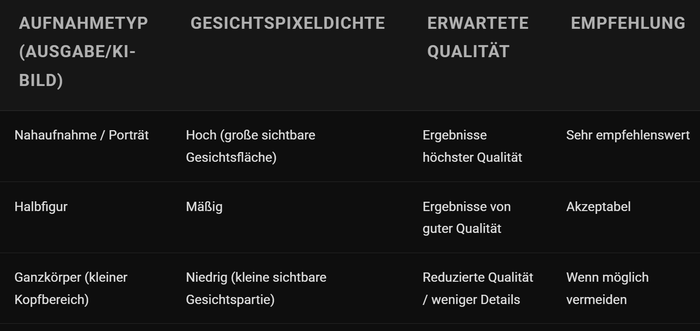
Die Komplexität einer Szene beeinflusst direkt die Erkennbarkeit und die Genauigkeit der Darstellung. Es gilt stets ein Gleichgewicht zwischen präziser Identitätswiedergabe und filmischem Storytelling zu finden.
Beispielbild: Das nachfolgende Bild zur Fußball WM haben wir in mehreren Schritten mit ChatGPT erstellt, dies ist das Basisbild um die Image2Filter Funktion zu zeigen

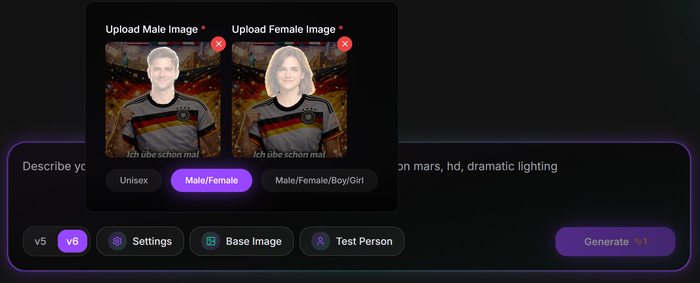
Für die später in Ihrem Event auswählbare KI-Szene muss bei der Filtererstellung entschiedenen, welche/s Basisbild/er erstellt werden:
- Unisex -> ein Basisbild für alle (1x Aufwand)
- Male/Female -> je Geschlecht ein Basisbild (2x Aufwand)
- Male/Female/Boy/Girl -> jeweils ein Basisbild (4x Aufwand)
Nachfolgend haben wir "Male/Female" als Vorgabe definiert. In den folgenden Beispielen wurden nur die Köpfe zur Visualisierung maskiert. Grundsätzlich würde man zusätzlich noch die Arme maskieren um bei verschiedenen Hauttypen ein realistisches Ergebnis gezeigt wird.


Wenn das Bild maskiert ist, beginnt die Arbeit durch "depth strength" und "denoise strength" das KI-Ergebnis zu optimieren. Zum einen muss die KI das Bild so generieren, dass es dem Maskierungsbereich angepasst wird, zum anderen sollte aber ein möglichst hoher Wiedererkennungswert der fotografierten Person bestehen.
Nachfolgend sehen Sie das Testbild und die verschiedenen generierten Ergebnisse:

Originalbild







Wir testen also die Einstellungen soweit bis ein gutes Ergebnis erreicht ist.
Wenn dies der Fall ist, speichern diesen Image2Filter als vorläufige Version. Danach beginnen die Testarbeiten mit verschiedenen Personen/Testbildern. Wenn dies erfolgreich ist, wird die Szene für das Event gespeichert.
Dieser komplette Testaufwand erfolgt für weitere Vorlagen, wenn es bsp. eine männliche UND weibliche Szene geben soll (alternativ unisex) oder auch noch für Mädchen und Jungen.
Neben der Maskierung des Kopfes ist auch der (Teil-) Körper möglich ...
Im folgenden Beispiel ist das Ziel den Hintergrund mit der Schrift beizubehalten, aber die Person komplett mit dem fotografierten Gast auszutauschen.


Testperson Ganzkörper

Ergebnis

Per Promt wird der fotografierte Gast in die Maskierung hineingesetzt, mit "replace the exact same person, adapt bodytype to person" erfolgt der 1:1 Tausch. Wenn man möchte, dass diese Person noch bestimmte Kleidung trägt wie "wearing german soccer outfit" erfolgt dies per Textbefehl, allerdings kann es hierbei ggf. zu Abweichungen kommen und das Ergebnis ggf. nicht ganz perfekt sein.
Preise Individualfilter
Wir entwickeln individuelle KI-Erlebniswelten für Dein Event – abgestimmt auf Marke, Zielgruppe und Kampagnenziel. Aus einem normalen Foto wird ein aufmerksamkeitsstarkes Eventmotiv, das Gäste begeistert, geteilt wird und Deinen Messestand oder Deine Veranstaltung sichtbar macht.
WICHTIG: Folgende Kosten für Individualfilter entstehen nur einmalig. Wenn wir mehr als einmal zusammenarbeiten, entstehen diese Kosten für weitere Events natürlich nicht, wenn die KI-Szene entsprechend hinterlegt ist.
1) TEXT2FILTER - Einzelszene -> Interpretiert Menschen in neuen Posen und Szenen
Paket S: 1 KI-Szene = 200€
Paket M: 3 KI-Szenen = 500€
Paket L: 5 KI-Szenen = 800€
2) TEXT2FILTER - Gruppenszene -> Bewahrt die ursprüngliche Pose. Kleidung, Szene und Hintergrund werden generiert (für 1-5 Personen gut nutzbar)
Paket S: 1 KI-Szene = 200€
Paket M: 3 KI-Szenen = 500€
Paket L: 5 KI-Szenen = 800€
3) IMAGE2FILTER - Einzelperson -> Es besteht eine feste Bildvorlage, bsp. nur der Kopf oder der Körper wird durch Maskierung ausgetauscht.
Paket S: 1 KI-Szene = 600€ (unisex), 800€ (männlich + weiblich)
Paket M: 3 KI-Szenen = 1500€ (unisex), 2000€ (männlich + weiblich)
Paket L: 5 KI-Szenen = 2400€ (unisex), 3200€ (männlich + weiblich)
bei Ganzkörpermaskierung/-austausch mit TEXT2FILTER-Erweiterung je +200€
Alle genannten Preise verstehen sich als Nettopreise zzgl. der gesetzlichen Umsatzsteuer in Höhe von derzeit 19 %.
KI-Kundenprojekt expert Warenvertrieb GmbH
(IMAGE2FILTER - Gesichtstausch männlich/weiblich)
Die expert SE mit Sitz in Langenhagen ist eine Handelsverbundgruppe für Consumer Electronics, Informationstechnologie, Telekommunikation, Entertainment und Elektrohausgeräte. Für über 14.000 Mitarbeiter ist expert deutschlandweit ein starker und verlässlicher Arbeitgeber. In der über 60-jährigen Unternehmensgeschichte hat expert seine starke Position im Markt gefestigt und ist heute zweitgrößter Elektronikfachhändler in Deutschland.
Im Rahmen der KOOP 2026, die gemeinsame Kooperations- und Ordermesse von EURONICS Deutschland eG und expert, feierte vom 1. bis 2. März 2026 eine erfolgreiche Premiere auf dem Messegelände Hannover. Mit über 1.200 Teilnehmern und Fokus auf die "expert-Strategie 2030+" bot die Veranstaltung eine zentrale Plattform für Consumer Electronics, IT und Hausgeräte. Die KI-Fotobox hat Erinnerungen festgehalten.
Es wurde die WM-Kampagne "Bereitmachen zum Jubeln" mit der KI-Fotobox unterstützt. Mit der Individualisierung IMAGE2FILTER wurde als Highlight mit Rudi Völler als Testimonial ein Filter als weibliche und männliche Version erstellt, dadurch waren die Gäste in der Lage ihr virtuelles Foto mit Rudi Völler als Erinnerung mitzunehmen.
Zusätzlich wurden drei Einzelfilter TEXT2FILTER passend zum Motto entwickelt, wodurch die Gäste als Fußballspieler oder Superheld auf dem Fußballplatz oder jubelnder Fan in der Stadionkurve waren. Ein tolles Markenevent mit erinnerungswürdigen Eindrücken.





Die KI-Bilder wurden noch mit einem älteren Generierungsmodell erstellt, das aktuell Modell wurde qualitativ verbessert und es werden u. a, klarere intensivere Farben dargestellt.
KI-Kundenprojekt von Ruwisch & Zuck
(TEXT2FILTER - Gruppenszene )
Ruwisch & Zuck – Die Käsespezialisten GmbH & Co. KG ist ein traditionsreiches, inhabergeführtes Großhandelsunternehmen für Käsespezialitäten mit Sitz in Hannover-Anderten. Der 1903 gegründete Betrieb beliefert den Handel mit über 2.400 internationalen Käsesorten und betreibt das European Cheese Center.
Im Rahmen von Hausmessen werden Lieferanten und Produkte den Kunden vorgestellt. Wir von Hannoverbox Events durften bereits zum zweiten Mal erinnerungswürdige Momente mit unserer KI-Fotobox schaffen - und das mit vollem Erfolg - die Kunden sind begeistert von der KI-Fotobox, haben ihre Ausdrucke an Team-Boards oder Kühlschränken hängen und teilen ihre digitalen KI-Erinnerungen in WhatsApp-Gruppen, LinkedIn, o. ä.
Neben einigen Standard-KI-Szenen mit Superhelden, Magiern, Prinzessinnen, Piraten, Retro-Gangstern und vielen mehr haben wir kundenindividuelle "Käse-Szenen" entwickelt. Dazu
- besprechen wir mit dem Kunden individuelle Wünsche
- erstellen erste Ideen für KI-Szenen
- stellen diese dem Kunden vor und konkretisieren die Szenen
- Kunde entscheidet sich für die finalen Szenen
- wir testen die finalen Szenen in mehreren Schritten
- die Szenen werden im Event bereitgestellt
Es wurden individuelle Szenen entwickelt






Diese Szenen sind für das Event flexibel nutzbar, d. h. 1-4 Personen sind kein Problem. Auch 6-7 Personen waren teils machbar, das kann aber nicht immer garantiert werden, da die KI entsprechend des realen Fotos Männer, Frauen und ggf. Kinder selektieren muss und anschließend die passende Kleidung sowie die Szene erstellen.
Highlights waren die Fotos vor dem "Schloss aus Käse" oder die "Käse Oscars" ...







